ABBYY FineReader 12使用教程 让你轻松识别图片文字
时间: 2018-07-13
来源:当下软件园
A+
ABBYY FineReader 12是一款非常专业的OCR图文识别软件。该软件可快速方便地将扫描纸质文档、PDF文件和数码相机的图像转换成可编辑、可搜索的文本,下面小编就来跟你讲讲具体的使用方法。
步骤一:首先打开需要转换的图像或PDF文件,看一下有哪些语言文字;
步骤二:运行ABBYY FineReader 12,在“文档语言”下拉列表中选择“更多语言”;
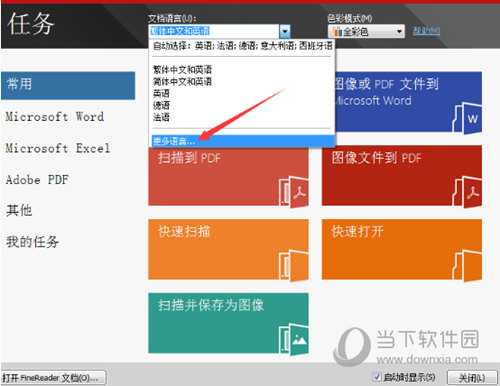
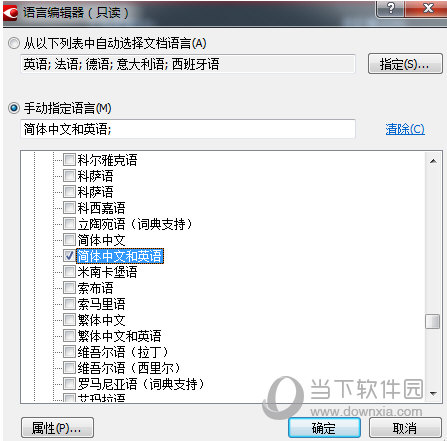
步骤三:在“语言编辑器”中勾选包含的语言“简体中文和英语”,点击“确定”;
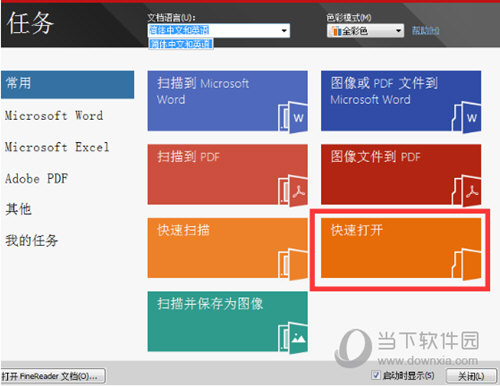
步骤四:返回“任务”,点击“快速打开”;
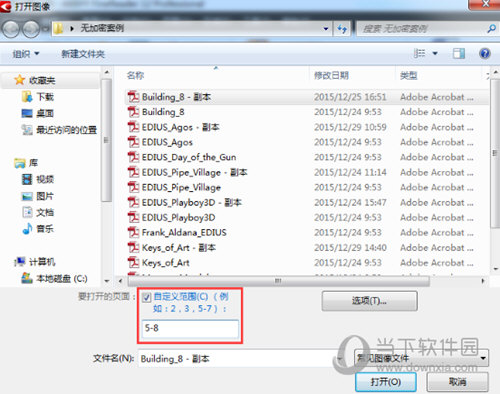
步骤五:弹出“打开图像”对话框,选择需要转换的文件,也可以选择多个文件批量识别转换,例如选择PDF文件,勾选自定义页面范围,输入“5-8”页面识别,然后点击“打开”;
步骤六:在“主工具栏”上点击“读取”,读取所有的未识别的页面;

步骤七:ABBYY FineReader 12将自动分析页面不同类型的区域,如文本、图片、背景图片、表格和条形码,在“图像”窗口绘制和调整未能正确识别的检测区域,调整区域之后请再次点击“读取”以识别;
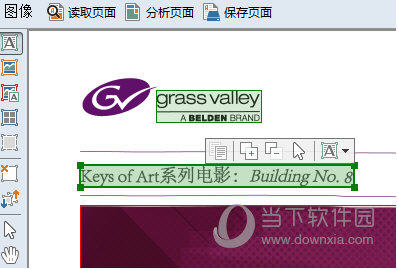
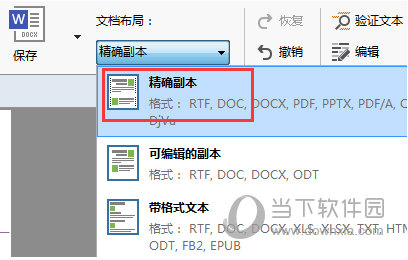
步骤八:如果“文本”窗口识别版面和源文件版面相差太大,在“主工具栏”将“文档布局”选择为“精确副本”;
步骤九:在“文本”窗口会将可能错误的字符以蓝色背景颜色显示出来,便于校对更正,可以右键文字以显示原图像和待选字符,再选择正确字符,对没有正确识别字符直接手动输入更正;
步骤十:校对完成之后,在“主工具栏”上选择“另存为Microsoft Word文档”,或选择菜单“文件”-“将文档另存为”-“Microsoft Word文档”,也可以保存为其他可编辑的格式。




